

ITインフラエンジニア採用
変化の早い事業拡大に対応できるシステム基盤をAWSに構築するなら、SREを導入するのが効果的です。SREの考え方やエンジニアのスキルを導入すれば、AWSという強力なクラウドプラットフォームを最大限に活用できます。
そこで本記事では、AWSにおけるSRE導入の重要性や具体的なメリットなどを解説します。運用の負担を減らし、サービスの品質を向上させるためにも、今回紹介する観点を実践に役立ててみてください。
AWS環境で継続的かつ安定したサービスを提供するため、多くの企業でSREの考え方が取り入れられています。SRE(Site Reliability Engineering)とは、ソフトウェア開発の手法を用いてシステムの信頼性を継続的に高めていく取り組みです。
AWSはクラウドサービスであり、システムを構築するだけで事業が成功するわけではありません。構築後にシステムを安定稼働させながら、ユーザーに快適なサービスを届ける運用が事業成長に欠かせない要素です。
関連記事:SREとは?導入のメリットやインフラエンジニアとの関係性を解説
AWSの設計思想とSREの考え方は親和性が高く、両者を組み合わせることでシステムの信頼性向上を期待できます。AWSのフレームワークでは「信頼性」が重要な柱の一つとして位置づけられているのも特徴的です。
AWSが重要視する信頼性とは、単にシステムが停止しないようにする対策ではありません。障害時の迅速な検知と自動復旧できるような設計であり、運用を見据えて障害に強いシステムの構築を目指すSREの考え方と共通しています。
従来のサーバー環境に比べて、多くのサービスが連携するクラウド環境は仕組みが複雑化しています。設計段階のミスによって、運用開始後に以下のようなトラブルを引き起こす可能性も少なくありません。
このようなリスクを避けるためにも、AWSではシステムの設計段階からSREの視点を取り入れ、安定稼働する仕組みづくりが重要視されています。
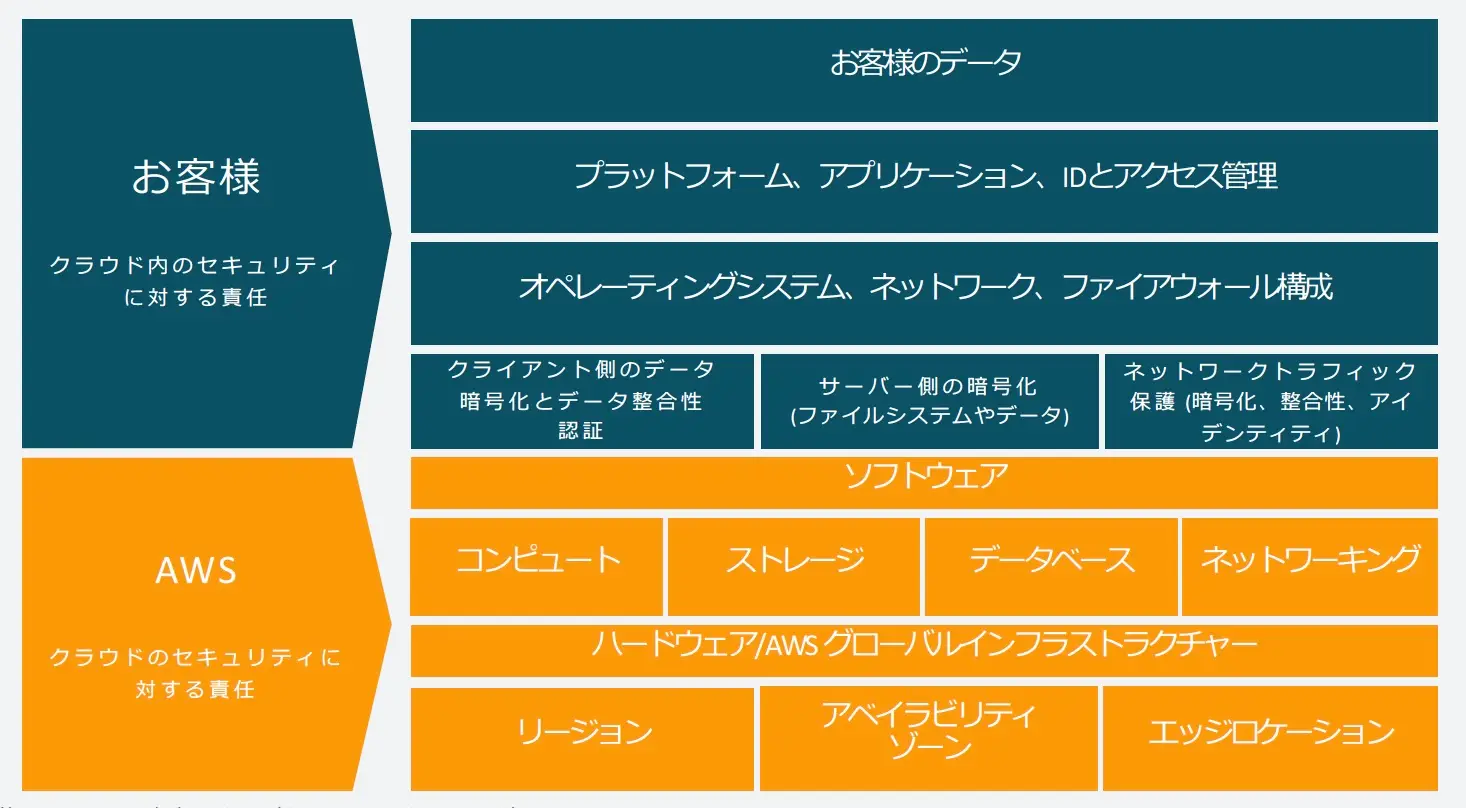 ▲出典:責任共有モデル – Amazon Web Services(AWS)
▲出典:責任共有モデル – Amazon Web Services(AWS)
AWSでは「共有責任モデル」の考え方を採用しており、以下のようにサービスの安定運用に対する一部の責任は利用者側にあります。
サーバーやネットワークなど、クラウドの基盤部分の責任はAWSが負います。一方で、アプリやデータの管理、パフォーマンスの監視などは利用者側の責任範囲です。
つまり、インフラをAWSに移行しただけでは、運用の負担がなくなるわけではありません。システムの信頼性を維持し、継続的に高めていくためには、利用者側で運用の仕組みをきちんと整える必要があります。
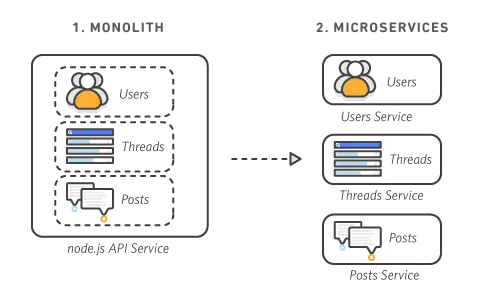 ▲出典:マイクロサービスの概要 | AWSさまざまな機能を独立したサービスとして利用できるAWSでは、マイクロサービスアーキテクチャを実現しやすい環境が提供されています。「マイクロサービス」とは、一つの巨大なシステムを構築するのではなく、機能ごとに独立した小さなサービスを組み合わせて動かす仕組みです。
▲出典:マイクロサービスの概要 | AWSさまざまな機能を独立したサービスとして利用できるAWSでは、マイクロサービスアーキテクチャを実現しやすい環境が提供されています。「マイクロサービス」とは、一つの巨大なシステムを構築するのではなく、機能ごとに独立した小さなサービスを組み合わせて動かす仕組みです。
このアーキテクチャとAWSは相性がよく、サービスを増やして段階的に拡張しやすいメリットがあります。一方で各サービスが複雑に連携するため、システム全体の状況を把握しにくいマイクロサービスならではのデメリットも考慮が必要です。
そこで、システムの信頼性や可用性を客観的に評価するため、SREで用いられている指標が役に立ちます。たとえば、SLO(Service Level Objective)の指標を活用することで、以下のように数字に基づく状況判断が可能です。
AWSのメリットは、事業の成長にあわせてシステムを柔軟に拡張できる利便性です。しかし、サービスの数が増えるにつれて、運用が複雑化しやすいデメリットもあります。
AWSの運用面のデメリットを解消するには、SREの導入が効果的です。ここからは、SRE導入によって得られるメリットを以下の観点で解説します。
SRE導入の目的の一つは、手作業による運用の「自動化・標準化」です。運用の自動化によって得られるメリットには、以下のような例が挙げられます。
SREでは、日々繰り返し発生する付加価値が生まれにくい手作業(トイル)の削減を目指します。トイルの削減はSREの目的の一つであり、以下の運用業務の改善に効果的です。
SREで用いられる指標を活用することで、以下のように数値に基づく品質管理が可能です。
たとえば、AWSの運用監視サービス「Amazon CloudWatch」を活用すれば、サービスの利用時間やレイテンシー(通信の遅延時間)などの実数値(SLI:サービスレベル指標)を測定可能です。そして、測定したSLIをもとに、設定した目標値(SLO:サービスレベル目標)を継続的に監視します。
従来の運用手法のように、サービスが「動いているかどうか」を監視するのではありません。目標値(SLO)に対する実数値(SLI)のチェックにより、より信頼性のある品質管理につながります。
SREには開発チームと運用チームの連携を強化し、共通の目標(信頼性)に向かって協力体制を整える役割もあります。従来の手法では分断されやすい開発・運用チームの障壁を取り除く「DevOpsの考え方」を推進するうえでも効果的です。
それぞれの目標が異なる開発チームと運用チームには、一般的に以下のような課題を抱えやすい傾向があります。
客観的なデータや指標を用いて中立的な立場から判断するSREは、チーム間の円滑な協力体制の構築に貢献します。たとえば、新機能のリリースや検証には、SREが用いるエラーバジェットの指標が効果的です。
具体的な数値をもとに方針を決定できるため、チーム間の合意形成がスムーズに進みます。
SREの導入効果を最大限に引き出すためには、いくつかの基本的な知識を理解しておきましょう。とくに、これから解説する「指標」「可観測性」「IaC」の概念は、SREを実践するうえで土台となる要素です。
| 指標 | 概要 | 目的 | 参考例 |
|---|---|---|---|
| SLA (Service Level Agreement: サービスレベル合意) | サービス提供者と利用者間で合意したサービスレベルに関する契約 | サービスの品質を保証し、利用者と提供者間の認識を一致させる | 月間稼働率99.9%を保証 |
| SLO (Service Level Objective: サービスレベル目標) | システムの信頼性や可用性に関する具体的な目標値 | システムの信頼性や可用性を定量的に管理し、改善目標を設定する | 月間稼働率99.95%を目指す |
| SLI (Service Level Indicator: サービスレベル指標) | SLOの達成度を測るための具体的な指標 | SLOの達成状況を監視し、問題発生時には迅速に対応する | システムの稼働時間、エラー率、レイテンシなど |
| エラーバジェット (Error Budget) | SLOで定めた目標値を達成できなかった場合に許容されるエラーの範囲 | 新機能リリースや実験などのリスクを管理し、システムの安定性と開発速度のバランスをとる | 月間稼働率99.95%のSLOに対するエラーバジェットは0.05% |
| 平均復旧時間 (MTTR:Mean Time to Recovery/Repair) | システム障害発生から復旧までの平均時間 | 障害発生時の対応速度を評価し、復旧プロセスの改善を図る | 障害発生から1時間以内に復旧 |
| 平均障害間隔 (MTBF:Mean Time Between Failures) | システム障害発生から次の障害発生までの平均時間 | システムの安定性を評価し、予防保全に役立てる | 平均1か月に1回以下の障害発生 |
| 稼働率 (Uptime) | システムが正常に稼働している時間の割合 | システムの可用性を示す基本的な指標 | 99.99% |
上表のようにSREの導入では、サービスの信頼性を客観的に評価するための指標が用いられます。具体的な数値に基づいて状況を把握することで、感覚的な判断ではなく合理的な意思決定が可能です。
各指標の概要と目的を理解しておくことで、AWS環境でSREを導入するときに重視すべき観点が明確化されます。すべての指標を取り入れるのではなく、目的に応じて必要な指標を選定する判断が大切です。
SREの実践において、システムの内部状態を分析データから把握する「可観測性」と呼ばれる考え方が重要です。可観測性の把握には、指標だけでなくシステムから出力されるログなども用いられます。
可観測性が高まることで、障害発生時に「なにが原因か」「どこが影響範囲か」のスムーズな特定が可能です。そして、SREでは可観測性をもとに、運用改善・障害対応・リスク低減などの対応を実施します。
AWSでは、以下のようなサービスで可観測性の構築をサポートしています。
| Amazon CloudWatch |
|
| AWS X‑Ray |
|
| AWS CloudTrail |
|
IaC(Infrastructure as Code)は、SREが目指す運用の自動化と標準化を実現するための手法です。インフラの構成を、プログラムのコードのようにファイルで記述・管理します。
IaCによるインフラ構成のコード化には、以下のようなメリットがあります。
以下は、AWS環境でIaCを実現する主要なツールです。
| AWS CloudFormation |
|
| AWS Cloud Development Kit(CDK) |
|
| Terraform |
|
AWS環境でSREの役割を担うエンジニアには、以下のスキルが求められます。
SREエンジニアの採用・育成の場面では、2つの側面に分けてスキルを把握する必要があります。これから解説する内容を採用・育成の計画に活かしてみてください。
関連記事:SREの関連資格を徹底調査!人材採用時の有用性も解説
SREエンジニアには、以下の観点でAWSを構築・運用するテクニカルスキルが求められます。
| テクニカルスキル | 概要 | 参考例 ()内は主要ツール・言語など |
|---|---|---|
| AWSのインフラ設計・運用スキル | 信頼性を設計するスキル (冗長化・スケーリング設計・フェイルオーバー構成など) |
|
| モニタリング・アラート設計スキル | SLOをもとに監視指標(SLI)を定義・閾値を設定するスキル |
|
| 運用業務の自動化・効率化スキル | トイル(手作業)を自動化し、運用負担を減らすためのスクリプト設計・CI/CD構築スキル |
|
他部署と連携する機会もあるSREエンジニアには、以下のように円滑な人間関係を築きながら課題解決に導くソフトスキルも求められます。
| ソフトスキル | 概要 | 対応例 |
|---|---|---|
| 論理的思考力 |
| Amazon CloudWatchのログやメトリクスを分析して仮説立案・検証する |
| 問題解決力 |
| 遅延の根本的な原因に対処するため、AWS X-Rayでリクエストの流れを追跡する |
| コミュニケーション力 |
| エラーバジェットの指標を用いて、客観的な根拠をもとに合意形成を図る |
AWS環境でSREを導入するには、専門的な知識やスキルをもつ人材の確保が欠かせません。エンジニアを確保する方法として正社員採用が一般的ですが、採用市場に人材が少ないSREの領域ではその他の選択肢も視野に入れるのが効果的です。
たとえば、経験豊富な即戦力を求めるなら、派遣会社やフリーランスの活用も有効な手段です。自社の状況やSRE導入のフェーズにあわせて、最適な人材確保の方法を検討してみましょう。
外部委託を検討する場合は、契約形態について比較している以下の関連記事も参考にしてみてください。

長期的な視点で組織にSREの文化を根付かせたい場合は、正社員採用が適しています。以下は正社員採用の主なメリットです。
ただし、以下のようなデメリットも考慮する必要があります。
SREは比較的新しい概念であり、高い専門性が求められます。採用市場に経験豊富な人材が少ないため、採用活動が長期化する可能性を考慮しておきましょう。
エンジニアが在籍する人材派遣会社に依頼すれば、SREの導入に対応できる人材を確保できます。とくにSREの導入が必要になるタイミングに絞り、柔軟に人員を確保できるのも人材派遣を活用するメリットです。
また、報酬の支払いは労働時間に基づいて計算されるため、人件費を固定費ではなく、業務量に応じた変動費として管理できます。
ただし、派遣会社によって、在籍するエンジニアのスキルレベルに差がある可能性もあります。自社のAWS環境や求めるSREの役割にマッチするかどうか、事前のスキル確認が欠かせません。
関連記事:SREにエンジニア派遣は適しているのか?メリット・デメリットを解説
プロジェクトの期間にあわせて即戦力となるSREエンジニアを求めるなら、正社員採用よりもフリーランスの活用が効果的です。要件にあわせて人材を募集できるため、求める業務スキルにマッチする即戦力を確保しやすい傾向があります。
また、プロジェクトの規模や期間にあわせて人員を調整できるため、人件費を最小限に抑えやすいのも魅力です。候補者の経験やスキルを慎重に評価するためには、必要に応じてエージェントサービスの活用も検討してみましょう。
関連記事:フリーランスのSREエンジニアとは?メリットと人材選定ポイントも紹介
AWSで構築したサービスの安定性を高め、事業を成長させるためには、SREの考え方を取り入れた運用が欠かせません。システムの信頼性を継続的に改善したり、開発チームと運用チームの連携を強化したりするには、SREエンジニアがもつ専門的な知識と役割が適しています。
指標に基づく分析や状況判断には専門知識が求められるため、自社で正社員を教育するよりも外部の人材を確保するほうが効果的です。とくに費用対効果と契約の柔軟性を重視するなら、専門的なスキルをもつフリーランスの活用も検討してみてください。
フリーランス専門のエージェントサービス「クロスネットワーク」では、SREの経験も豊富なインフラエンジニアを迅速にマッチングいたします。プロジェクト単位でも柔軟に対応しており、初めての業務委託を検討する企業でも安心です。
クロスネットワークに相談いただければ、最短3営業日でのアサインも可能です。また、週2〜3日の依頼にも対応しているので、解決したい課題やご要望に応じて柔軟な外注をサポートいたします。
サービス資料は【こちら】から無料ダウンロードが可能です。柔軟な契約条件でインフラエンジニアを確保するなら、ぜひ気軽に【お問い合わせ】ください。平均1営業日以内にご提案します。

元エンジニアのWebライター。自動車部品工場のインフラエンジニアとして、サーバー・ネットワークの企画設計から運用・保守まで経験。自分が構築したインフラで数千人規模の工場が稼働している達成感とプレッシャーは今でも忘れられない。





